

Blog

Google é processado e acusado de roubar dados para treinar IA
13 de julho de 2023 / Tecnologia / por Comunicação Krypton BPO
O escritório de advocacia Clarkson Law Firm processa o Google nos EUA sob acusação de que a Gigante da Web coletou dados de usuários sem consentimento e violou direitos autorais para o treinamento de ferramentas de IA. A ação judicial também visa processar a DeepMind, empresa-irmã do Google, e a Alphabet, controladora de ambas.
De acordo com o documento da denúncia, o Google estaria “roubando secretamente tudo o que foi criado e compartilhado na internet por centenas de milhões de americanos” para desenvolver suas linguagens de IA, como o Bard. O mesmo escritório de advocacia também processou a OpenAI, detentora do ChatGPT, no mês passado.
A conselheira-geral do Google Halimah DeLaine Prado disse que a acusação “não tem base” e que a empresa deixou claro “por anos que usamos dados de fontes públicas para treinar modelos de IA em serviços como o Google Tradutor, de forma responsável e alinhada com nossos princípios de IA”.
No entanto, vale a ressalva de que a menção à inteligência artificial só surgiu há pouco tempo na política de privacidade.
Google mudou política de privacidade para incluir IA
O Google mencionou claramente o uso de dados públicos para treinar IA na atualização mais recente da política de privacidade, divulgada no começo de julho. O trecho informa que a empresa pode “coletar informações disponíveis publicamente on-line ou de outras fontes públicas para ajudar a treinar os modelos de IA do Google e criar recursos como o Google Tradutor, o Bard e recursos de IA na nuvem”.
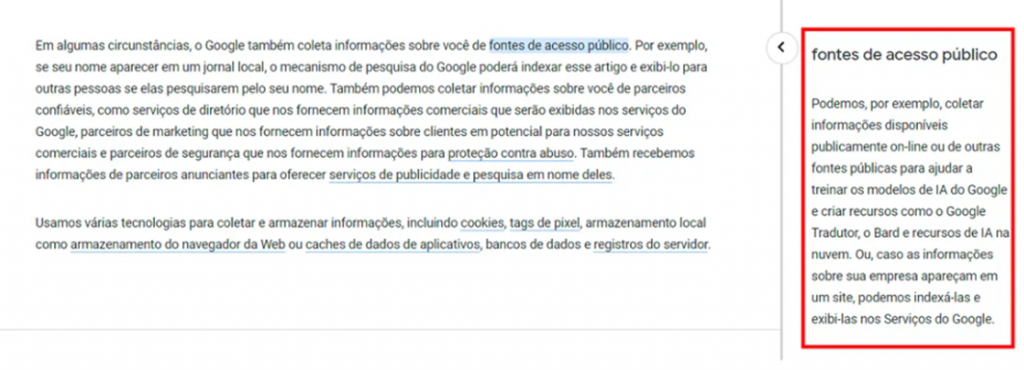
Nas versões anteriores, não havia menção aos serviços de IA — no lugar disso, a empresa dizia somente que os dados eram usados para “ajudar a treinar os modelos de idiomas do Google e criar recursos como o Google Tradutor”.
Uso de direitos autorais por IA é alvo de processos
Paralelamente ao desenvolvimento dos modelos de IA generativa, surge a preocupação sobre como essas ferramentas coletam os dados e podem infringir direitos autorais em livros, artigos científicos, músicas e outros documentos.
A comediante e escritora Sarah Silverman processou a Meta e a OpenAI pelo suposto uso ilegal de seus livros para o treinamento dos modelos de IA. Além disso, as ferramentas geradoras de imagens também já foram processadas por artistas visuais.
Fonte: CanalTech
Posts relacionados

9 de janeiro de 2026 / Blog Tecnologia / por Comunicação Krypton BPO

8 de janeiro de 2026 / Blog Tecnologia / por Comunicação Krypton BPO

7 de janeiro de 2026 / Blog Tecnologia / por Comunicação Krypton BPO

3 de novembro de 2025 / Tecnologia / por Comunicação Krypton BPO

29 de outubro de 2025 / Tecnologia / por Comunicação Krypton BPO

9 de julho de 2025 / Tecnologia / por Comunicação Krypton BPO
 Documentos que a empresa precisa manter organizados ao longo do tempo23 de fevereiro de 2026
Documentos que a empresa precisa manter organizados ao longo do tempo23 de fevereiro de 2026 Como funciona o acompanhamento de processos paralegais na prática16 de fevereiro de 2026
Como funciona o acompanhamento de processos paralegais na prática16 de fevereiro de 2026 Como o BPO apoia a tomada de decisão em empresas de maior porte11 de fevereiro de 2026
Como o BPO apoia a tomada de decisão em empresas de maior porte11 de fevereiro de 2026 Impactos da Lei Complementar nº 224/2025 – Atenção ao enquadramento tributário13 de janeiro de 2026
Impactos da Lei Complementar nº 224/2025 – Atenção ao enquadramento tributário13 de janeiro de 2026 Os 4 níveis de avaliação em treinamento9 de janeiro de 2026
Os 4 níveis de avaliação em treinamento9 de janeiro de 2026